

在 AI 技术飞速发展的今天,如何高效地将多个专业模型的能力融合到一个通用模型中,是当前大模型应用面临的关键挑战。全量微调领域已经有许多开创性的工作,但是在高效微调领域,尚未有对模型合并范式清晰的指引。
因此,中科院、中山大学、北京大学的研究团队针对高效微调模型合并,提出了「方向鲁棒性」的概念,首次揭示了参数高效微调(PEFT)模块合并失败的根本原因是「方向不鲁棒」,而非传统认为的「符号冲突」,并提供了一个简单高效、无需额外成本的解决方案(RobustMerge)。
对于正在构建能够快速适应多种任务、且节省计算资源的 AI 系统的开发者和研究者来说,这项研究无疑提供了一把关键钥匙,为多模态大模型的高效应用开辟了新的可能性。
目前,文章被 NeurIPS 2025 接收并评为 Spotlight(Top 3.1%),代码、数据集和模型已全面开源。

问题定义
在大模型时代,多模态大模型在提升任务性能的同时大大增加了计算量,由于过高的成本,动辄几十亿的参数使得并不是所有人都可以参与全量微调(Full Fine-Tuning, FFT)。于是,为了节省资源,参数高效微调(Parameter-Efficient Fine-Tuning, PEFT),特别是 LoRA,成了主流。其可以通过只更新模型的一小部分参数,达到快速适应下游任务的目的。
而由于 LoRA 模块参数的有限性,其通常只能适应某一个特定的下游领域。如果我们需要为每个任务训练一个专家模型,那么就会有一大堆针对不同任务微调出来的 LoRA 模块,个个都只能解答所在领域的问题。这就像拥有一个装满专业工具的箱子,但每次只能使用一件工具,这显然不是所希望的。
更现实的场景是,怎么把这些模型组合成一个通用模型,处理多种任务,从解答科学问题到识别图像等所有微调的任务呢?传统的方法如多任务学习(Multi-task learning)通过混合所有任务的数据进行训练实现这一点,但这种范式存在两大问题:
1.训练成本:在所有数据上进行联合训练的过程耗时耗力,成本不可控;
2.训练数据:出于安全性和隐私考虑,并不总是能够直接获取到所有的原始数据。
针对这种情况,模型合并 (Model Merging) 被提出,其通过某种加权融合的方式,可以使得多个在特定领域数据上微调好的专家模型合并成一个通用模型,整个过程既不需要重新训练,也不需使用原始数据,从而以最小的代价完成知识整合,已经被证明在大模型时代具有较好的通用性和泛化性。
然而,由于两种微调方法参数分布的显著差异,当在 FFT 时代被证明有效的模型合并方法(如 Ties-merging、DARE)被直接用于合并 PEFT 模块时,效果往往大打折扣,有时甚至不如未经微调的 Zero-Shot 模型。

图 1 左:FFT 参数和 PEFT 参数分布的显著差异。 右:PEFT merge 方法在已见任务和未见任务上的性能比较
核心贡献:RobustMerge 针对 PEFT merge 这一问题,探究 PEFT merge 方法少且现有方法性能不佳的原因,找到问题的核心 ——方向鲁棒性(Direction Robustness),并给出了一个优雅的可行方案大幅提升 PEFT merge 性能。
研究动机与发现
首先需要研究 LoRA 模块与全量参数模块的区别。作者发现两个关键的区别:(1)LoRA 模块的参数分布显著大于全量微调的分布,说明其分布更广(Distinct Wider Distribution);(2)LoRA 天然的低秩性让其在 SVD 分解后的奇异值存在显著的差异(Stark Singular Values):
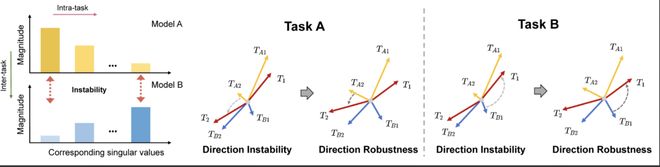
图 2 高效微调模型低秩模块在合并过程中的方向鲁棒性
基于以上观察,作者通过奇异值分解(SVD)的理论推导将 LoRA 模块的合并转化为各个奇异值向量的合并。合并时,这些不稳定的尾部方向很容易因干扰发生方向改变,从而引发性能的下降。
因此,可以得出,在 LoRA 合并的过程中,最重要的是维持方向稳定性。具体而言,由于数值更小,尾部奇异值的方向更加不鲁棒,需要通过某种方式维持其方向鲁棒性,进而增强多任务学习性能。
技术方法:RobustMerge
根据上述结论,成功的 PEFT 合并,关键在于保护低秩空间中每个奇异向量的方向。由于奇异值较大的方向更鲁棒,更不易被改变方向,故保护那些奇异值较小(但同样重要)的向量方向尤其重要,也是作者认为多任务性能下降的主要原因。
基于此,RobustMerge 提出了一个两阶段的合并策略:(1)修剪与参数互补缩放 (2)跨任务归一化。整个过程无需训练,即达到缩放增强尾部奇异值的方向稳定性,提升模型合并性能的目的。
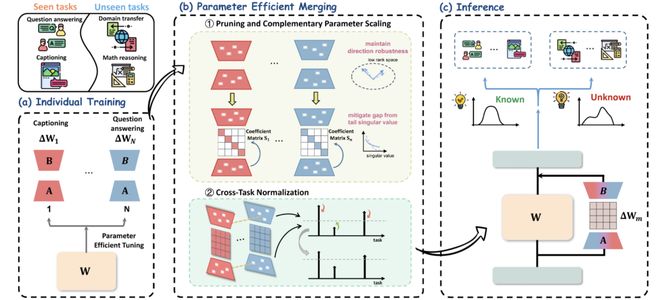
图 3 RobustMerge 详细方法示意图
第一步:修剪与参数互补缩放 (Pruning and Complementary Scaling)
1. 修剪无效参数:传统合并方法(如 Ties-Merging)是为全参数微调设计的,由于其分布特别狭窄,因此通常认为冲突主要来自参数符号的改变(正负)。但在 PEFT merge 中,冲突的本质是方向不稳定性,而更加广泛的参数分布使得数值上更大的参数更有可能改变奇异值的方向。
因此第一步,根据参数的绝对大小(Magnitude)决定无效参数,将每个 LoRA 模块中排名后 k% 的小参数直接置零的方式:
这一步能有效抑制冲突的同时,为稳定方向打下基础。
2. 参数互补缩放:接着设计一个对角矩阵 S 来弥补因为参数修剪带来的性能损失。文中观察到 LoRA 矩阵 A 和 B 的不对称性(A 呈分布均匀,B 呈高斯分布),从 A 矩阵的统计特性中构建一个对角矩阵 S,对角元素根据下式计算得到:

这一步相当于给那些容易发生方向改变的尾部奇异值方向自适应地给予了更大的系数,从而稳住它们的方向,达到增强方向鲁棒性的目的。整个过程完全是不需要训练的,而且在不显式分解 LoRA 矩阵奇异值的情况下高效地进行缩放,拿来即用,计算量极小,这在工程上是巨大的优势。
第二步:跨任务归一化 (Cross-Task Normalization)
由于每个任务的数据量和难度各不相同,会导致上一步计算出的矩阵 S 不平衡。例如,某个数据丰富的任务可能会因为拟合程度较高而不是因为自适应缩放本身获得过大的缩放系数,从而影响泛化性能。为此,作者对所有任务的矩阵系数进行归一化:
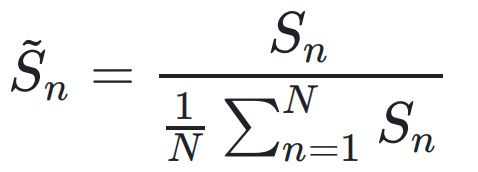
这确保了模型的参数不会因为数据量的不一致产生大小区分,从而保证泛化性能。
第三步:PEFT 模块合并
将经过调整的 PEFT 模块进行融合,得到每个 LoRA 部分的参数权重:

得到每个部分的权重后通过加权融合的方式即可得到具备多任务知识和性能的通用模型。
实验设计与结果分析
作者在多个基准上测试了 RobustMerge,同时自建了一个名为MM-MergeBench的基准来全面测试模型合并方法在多模态大模型上的性能,包含了 8 个已见任务(Seen Tasks,模型训练过的)和 4 个未见任务(Unseen Tasks,全新的挑战),覆盖了问答、分类、描述、推理等多种任务,同时验证已见任务的多任务性能和未见任务的泛化性能。
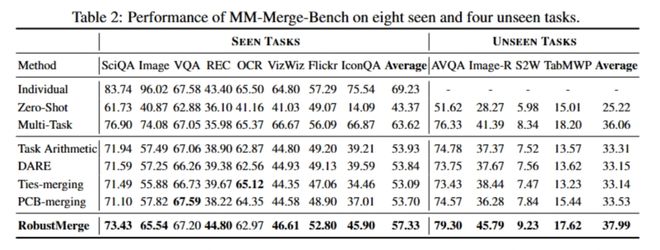
图 4 多模态基准 MM-MergeBench 上的性能
已见任务:作者使用在 8 个任务上分别单独训练得到的模型进行合并,得到一个通用模型,并对这 8 个任务的性能进行测试。图中可以看出,RobustMerge 的平均准确率相较之前的方法取得了显著提升 (3.4%),表明所提出的方法有效减少了任务间干扰,提升多任务性能。
未见任务:为了验证合并模型的泛化性能,作者将合并得到的通用模型在 4 个从未见过的全新任务上进行验证,发现模型平均性能提升 4.5%,某些指标甚至超越了联合训练得到的模型,这有力地证明了所提出方法的泛化能力,有助于其在真实世界的使用。
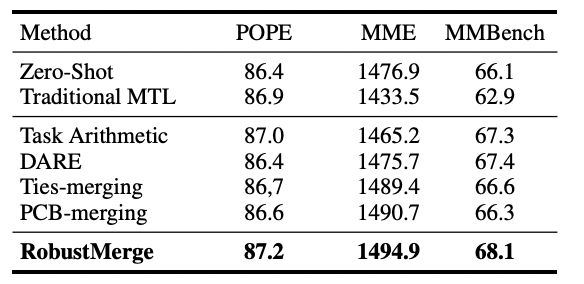
图 5 通用能力基准上的性能
通用能力测试:同时在通用能力基准,如 POPE、MME 上,RobustMerge 也取得了令人印象深刻的结果,进一步证明了其通用能力。
深入分析
作者通过指标验证和可视化,直观深入揭示了 RobustMerge 成功的机制。
1. 方向鲁棒性验证:为了量化所提出的方向鲁棒性,作者定义了方向相似性和奇异值保留比率,并进行实验来直观表明其在合并前后方向的变化。
实验证明,传统方法会导致方向的显著改变和数值的较大变化,而 RobustMerge 则能更好地维持小奇异值对应向量的方向和幅度。这有效地量化了方向鲁棒性,并有力地证实了所提出方法的有效性。
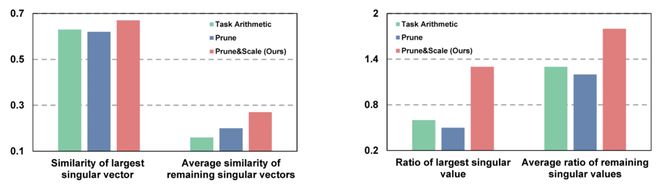
图 6 方向鲁棒性的量化指标验证
2. 奇异值分布的变化:作者展示了在不同层中矩阵奇异值分布的变化,发现所提出的方法可以很好地做到自适应缩放所有奇异值,同时使得更小的奇异值缩放倍数更多,达到增强方向鲁棒性的目的。
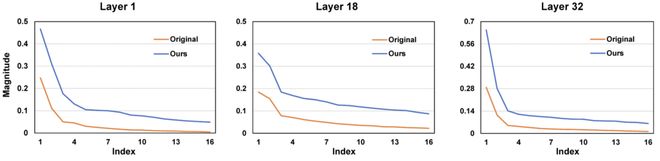
图 7 奇异值分布随不同层的变化趋势
总结
1. RobustMerge 和与传统方法最大的区别是什么?
答:核心区别在于问题定义和具体分析。TIES-Merging 等传统方法主要针对全量微调模型,认为合并的性能下降主要来自参数的符号冲突。而RobustMerge 则发现对于 PEFT 方法而言,性能不佳的根本来源是方向不稳定性。所以,RobustMerge 有望开启 LoRA 合并的全新范式。
2. 能用在其他 PEFT 方法上吗?
答:不仅可以用于其他 PEFT 方法,甚至有更广阔的应用前景,因为其方向鲁棒性的核心思想 —— 在合并高效微调的多模态大模型时,我们不应只关注参数的 「数值」,更应关注它们所代表的「方向」—— 具有很强的普适性。
RobustMerge 的成功给我们带来的道理是简单却深刻的:在处理多源异构信息融合问题时,不能简单地进行线性叠加。必须首先分析每个信息源的「强度」和「特性」,对弱但重要的信号进行保护和增强,同时对强信号进行适当的归一化,才能得到一个鲁棒且全面的融合结果。
这个思想可以应用在推荐系统、多模态数据分析等多个领域,这些都是未来重要的研究方向。
3. 有什么实际应用价值吗
答:当然!形式上,只要一个 PEFT 方法可以被分解为低秩矩阵的形式,需要两种或者多种模型进行某种合并,RobustMerge 的思路就有可能被借鉴和扩展。其应用场景包括但不限于:
它提供了一种低成本、高效率、保护隐私的模型融合方案,通过精巧的、基于数学原理的无训练操作,同样可以实现强大的模型能力整合,对于希望快速构建复杂 AI 应用的企业来说,吸引力巨大。