

近日,蚂蚁集团正式开源业界首个高性能扩散语言模型(Diffusion Large Language Model,dLLM)推理框架 dInfer。
在基准测试中,dInfer 将 dLLM 的推理速度相比于 Fast-dLLM 提升了10 倍以上,并在关键的单批次(batch size=1)推理场景下,作为首个开源框架实现了大幅超越经过高度优化的自回归(AR)模型的性能里程碑,在 HumanEval 上达到1011 tokens / 秒的吞吐量 。dInfer 通过一系列算法与系统协同创新,攻克了 dLLM 的推理瓶颈,兑现了其内生并行生成带来的推理效率潜力。
这不仅为开发者提供了即刻可用的高效推理框架,更标志着扩散语言模型这一全新的范式迈出了走向成熟的坚实一步。

理论的「翅膀」,现实的「枷锁」:扩散语言模型的推理困境
近年来,以自回归(Autoregressive,AR)范式为核心的大语言模型(Large Language Models)已经取得了巨大的成功,推动了智能问答、代码生成、智能体助手等领域的重大进步。然而,AR 生成范式也存在其固有瓶颈:生成过程完全依赖前序结果,必须逐词串行生成,这导致推理延时难以降低,即使 GPU 的并行计算能力强大也无用武之地。
作为一种全新的范式,扩散语言模型(dLLM)应运而生 。它将文本生成视为一个 「从随机噪声中逐步恢复完整序列」的去噪过程 。这种模式天然具备三大优势:
凭借这些优势,以 LLaDA-MoE 为代表的 dLLM 已在多个基准测试中,展现出与顶尖 AR 模型相媲美的准确性 。然而在推理效率方面,dLLM 理论上的强大潜能,却长期被残酷的现实「枷锁」所束缚。dLLM 的高效推理面临三大核心挑战:
高昂的计算成本:多步迭代去噪的特性,意味着模型需要反复对整个序列进行计算,这带来了巨大的算力开销 。KV 缓存的失效:dLLM 中的双向注意力机制,使得 token 对应的 KV 值在每次迭代中都会改变。这导致 AR 模型中「一次计算、永久复用」的 KV 缓存技术直接失效,使得推理过程异常昂贵 。并行解码的双刃剑:尽管理论上可以并行生成序列中的所有 token,但在难以精准刻画其联合概率分布的情况下一次性解码太多 token,极易引发彼此间的语义错配,导致「并行越多,质量越差」的窘境 。
这些瓶颈使得 dLLM 的推理速度一直不尽人意,其并行生成带来的效率沦为「纸上谈兵」。如何打破枷锁,释放 dLLM 在推理效率的潜能,成为整个领域亟待解决的难题。
dInfer:人人可上手的扩散语言模型高效推理框架
为彻底突破上述瓶颈,蚂蚁集团推出了 dInfer—— 一个专为 dLLM 设计的、算法与系统深度协同的高性能推理框架 ,可支持多种扩散语言模型,包括 LLaDA、 LLaDA-MoE、LLaDA-MoE-TD 等。
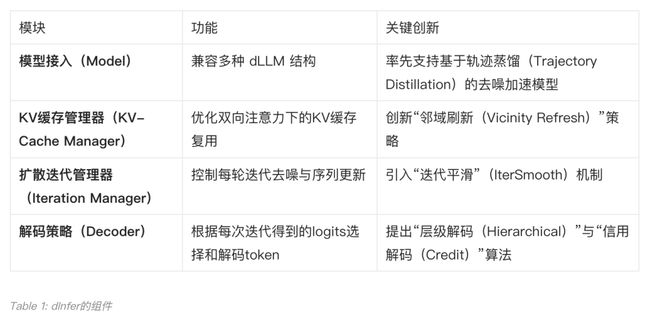
dInfer 的设计哲学是模块化与可扩展性,以系统性集成算法与系统优化。如下图所示,dInfer 包含四大核心模块:模型接入(Model)、KV 缓存管理器(KV-Cache Manager),扩散迭代管理器(Iteration Manager),和解码策略(Decoder)。
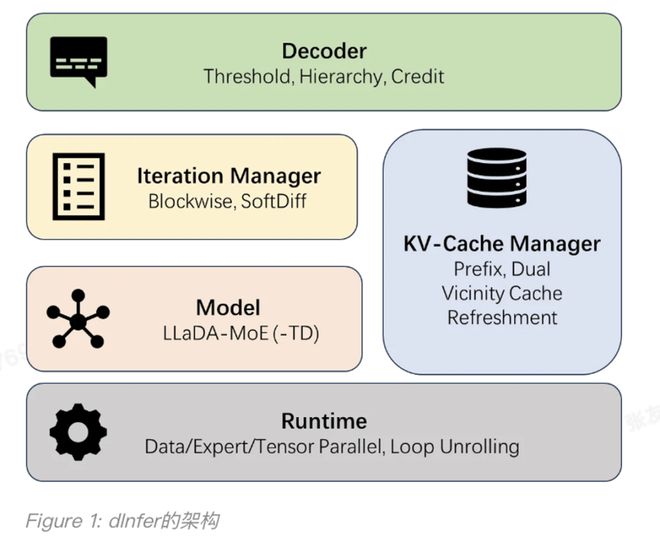
这种可插拔的架构,允许开发者像搭乐高一样,进一步组合和探索不同模块的优化策略,并在统一的平台上进行标准化评测 。更重要的是,dInfer 针对上述三大挑战,在每个模块中都集成了针对性的解决方案。
dInfer 如何「快」起来?
1.削减计算成本,控制生成质量:邻近 KV 缓存刷新 (Vicinity KV-Cache Refresh)
dLLM 使用双向注意力机制让模型获得更全局的视野,代价是每次解码会影响所有的 token 的 KV 值,导致 AR 模型依赖的 KV 缓存技术不能直接应用到 dLLM 上。如果不使用任何 KV 缓存,在一个 sequence 上的一次 diffusion 迭代会导致大量的计算。
为了削减计算成本,Fast-dLLM 提出的将 sequence 划分为 block,然后再逐个对 block 进行解码,并在当前解码 block 之外进行 KV 缓存的方法,可以有效降低 diffusion 迭代的计算成本。然而虽然利用上了 KV 缓存,但在大部分情况下,缓存中的 KV 实际上是过时的,因此会导致生成质量的下降。
为了缓解这一问题,dInfer 采取了一种邻近刷新的策略:KV 缓存过时的原因是 dLLM 中一个新 token 的确定,会影响全局所有 token 的 KV 表示。而dInfer基于「语义局部性」原理( 一个词的更新,对其近邻词的影响最大),在每次迭代解码一个 block 时,dInfer 只选择性地重新计算该区块及其邻近一小片区域的 KV,而让远处的缓存保持不变 。这好比修改文档中的一句话,你只需检查上下文是否通顺,而无需重读整篇文章。
这种策略结合 dInfer 的其它优化,在计算开销和生成质量之间取得了平衡,首次让 KV 缓存机制在 dLLM 上高效、可靠地运作起来。
2.系统优化:让 dLLM 的前向运算速度追上 AR
在利用上 KV 缓存之后,dInfer 选择了合适的 block 大小和 Vicinity KV-Cache Refresh 的范围,并做了一系列的系统优化,以使 dLLM 一次迭代的速度能追上运行在 SOTA 的推理服务框架如 vLLM 上的 AR 模型,包括:
3.并行解码:层级解码 (Hierarchical) 与信用解码 (Credit)
为了在保证生成质量的前提下,最大化并行解码的 token 数量,dInfer 提出了两种无需额外训练的解码算法 :
4.压榨每步迭代价值:迭代平滑 (Iteration Smoothing)
传统 dLLM 在每轮迭代中,只利用了置信度最高的 token 信息,而将其他位置的概率分布整个丢弃 。dInfer 的迭代平滑算法,旨在回收这些被浪费的信息 。
它基于未解码位置的 logits 分布得到该位置的加权 Embedding,并将其作为宝贵先验知识,平滑地融入下一轮迭代的 Embedding 中 。这极大地丰富了上下文信息,使得单次迭代解码的 token 数量平均提升了 30-40%。
此外,由于 dInfer 可以无障碍地接入多种扩散语言模型,此次率先支持了基于轨迹蒸馏(Trajectory Distillation)加速 diffusion 去噪过程的 LLaDA-MoE-TD 模型,推理性能更强。
实测数据:里程碑式的性能飞跃
在配备 8 块 NVIDIA H800 GPU 的节点上,dInfer 的性能表现令人瞩目。
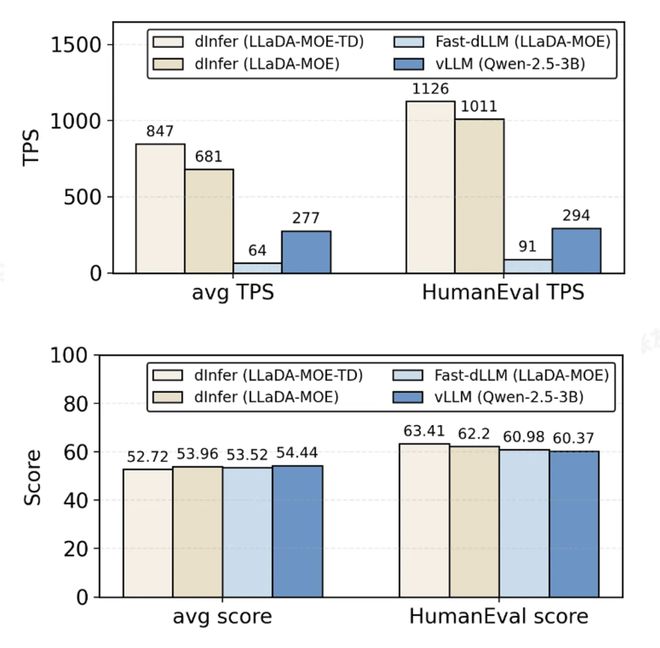
Figure2: 评测数据
更进一步,当结合轨迹蒸馏(Trajectory Distillation)技术(一种让模型学会 「跳跃式」去噪的后训练优化方法)后,dInfer 的平均推理速度飙升至 847 TPS,实现了超过 3 倍于 AR 模型的性能 。
开源开放:共建下一代 AI 推理新生态
dInfer 的诞生,不仅是一个工具的发布,更是一次 LLM 范式的试炼:它证明了扩散语言模型的效率潜力并非空中楼阁,而是可以通过系统性的创新工程兑现,使其成为 AGI 道路上极具竞争力的选项。
目前,dInfer v0.1 的全部代码、技术报告与实验配置已开源。
蚂蚁希望 dInfer 能成为:
dInfer 连接了前沿研究与产业落地,标志着扩散语言模型从「理论可行」迈向「实践高效」的关键一步。我们诚邀全球的开发者与研究者一同加入,共同探索扩散语言模型的广阔未来,构建更加高效、开放的 AI 新生态。