
Ling-1T给效率革命交了一份更贴近场景的答卷——万亿级储备,百亿级开销,产业级落地。规模、速度与推理精度,其实可以兼顾。
完全测不过来了。
仅仅一个 9 月,全球就有十余家主流玩家扎堆开源大模型—— BAT、蚂蚁集团、深度求索、Meta FAIR、Mistral AI 等轮番登场,开源数量较8月直接翻倍还不止,态势堪称井喷。
其中,中国力量格外亮眼。蚂蚁集团几乎以一场「开源风暴」刷屏整月:旗下百灵大模型密集上线 7 款新品,平均每四天就有一个新模型问世,在性能、效率与功能维度持续突破。
9 月 30 日开源的思考模型 Ring-1T-preview( Ring-1T 早期版本),首次把开源推理模型的「天花板」推到万亿参数级,连深度学习「三巨头」之一 Yann LeCun 都点赞,称「Impressive.」
这股势能还在高涨。10 月 9 日凌晨,百灵大模型再度出手,正式发布并开源通用语言大模型 Ling-1T ——蚂蚁迄今为止开源的参数规模最大的语言模型。至此,继月之暗面Kimi K2、阿里 Qwen3-Max 之后,又一位重量级选手迈入万亿参数LLM 「开源俱乐部」。
大象起舞:
万亿参数,也能轻盈推理
Ling-1T 自百灵大模型 「Ling 2.0 系列」,延续了蚂蚁自研的高效 MoE( Mixture of Experts )架构,它也是该系列的首款旗舰产品。而1T( Trillion,万亿)级的总参数规模,让人再次直观感受到开源模型的「体量战争」还在加速升级。
提到「万亿参数」,不少人的第一反应往往是:「堆料取胜」、「花费高昂」。模型越大,推理越冗长;算得快又省,又怕不够准。「精确」和「效率」,永远像在玩跷跷板,此消彼长。而 Ling-1T 正通过帕累托改进( Pareto Improvement ),改写这一刻板印象——
既不牺牲推理能力,又能显著提升思考效率,持续逼近几乎不可再改进的平衡点(帕累托最优)。
那么,Ling-1T 的「高质量输出」到底强在哪?官方晒出的成绩单显示,在多维基准测试中表现亮眼。
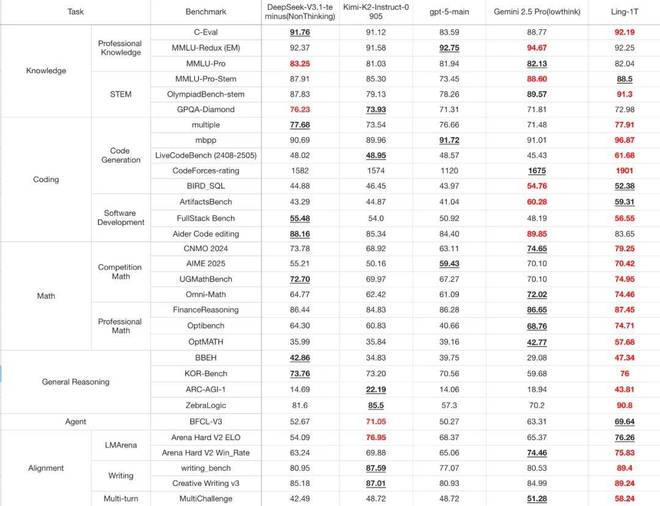
Ling-1T(最右列)与几款具有代表性的旗舰模型的比较,包括大参数量的开源模型(DeepSeek-V3.1-Terminus、Kimi-K2-Instruct-0905)与闭源 API(GPT-5-main、Gemini-2.5-Pro)。
最引人注目的是编程与数学推理( Coding & Math )两大核心维度的表现。这些被称为高推理密度的任务,是大模型能力的天花板所在,而 Ling-1T 仍稳居第一梯队。
例如,在 LiveCodeBench(真实编程推理任务) 上,Ling-1T 得分最高,显著高于 DeepSeek;在 ArtifactsBench(复杂软件逻辑建模) 中,得分59.31,仅次于Gemini-2.5-Pro。
数学方面,在综合测试中,Omni-Math 与 UGMathBench 双双突破 74 分大关,稳居领先位置;在 FinanceReasoning(金融推理)中表现更稳,达到 87.45,展现出强大的逻辑一致性与跨领域推理能力。
知识理解( Knowledge )维度同样出色。Ling-1T在多个关键数据集上均处于领先或并列领先位置:
C-Eval(92.19)、MMLU-Redux(92.25)、MMLU-Pro(82.04)、MMLU-Pro-STEM(88.5)、OlympiadBench(91.3)。
这些分数整体比 DeepSeek、Kimi、GPT-5 主干模型普遍高出1~3 个百分点,部分指标甚至逼近Gemini-2.5-Pro 的上限。
这表明它不仅知识密度高、泛化能力强,更具备深度思考与逻辑推理的内在一致性。
在 Agent 推理与多轮对话( Multi-turn Reasoning )场景中,Ling-1T 的表现同样亮眼。尤其在 BFCL-v3 与 Creative-Writing 等具备开放思维特征的任务中,展现出自然语言表达与思维连贯性的平衡能力——不仅「会答题」,还「懂思考」。
有意思的是,智商拉满并不等于很烧钱。
在 AIME-25(美国数学邀请赛 2025) 推理测试中,研究人员比较了各大模型的表现:
推理准确率 vs. 平均输出长度(即思考消耗的 token 数量)。
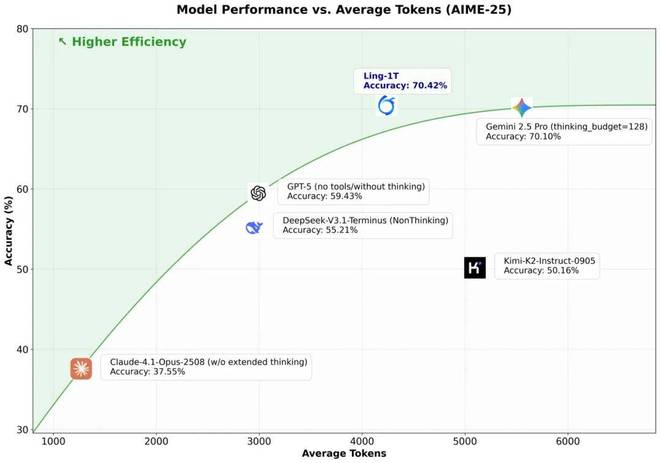
蓝色点代表Ling-1T,准确率高达 70.42%,与Gemini-2.5-Pro(70.1%)并列最高精度,但后者用了更长的输出(更多 token)。
与 Gemini-2.5-Pro 相比,Ling-1T 在更短的思考路径中,达到了同等甚至更高的推理正确率。
相比之下,GPT-5、DeepSeek-V3.1-Terminus、Kimi-K2-Instruct-0905、Claude-4.1-Opus-250B 等模型的准确率明显更低,要么输出冗长,要么思考效率不高,普遍落在右下方或中间区域。
亲自试一试
写到这里,不少人或许会问:听起来确实令人印象深刻,但这和普通人又有什么关系?也许你从未调用过 API,也不会去跑模型。但这些模型的能力,正在悄然渗透进你的日常生活。
在支付软件中,它让智能助理更懂你的「吃穿用度」;理财助手会帮你盯盘、诊基;身体不适时,健康助手知道如何给出初步建议,甚至协助对接医疗资源。而在写作、编程、设计等场景里,你常用的工具,也因为它而变得更聪明。
刚上手 Ling-1T,最直观的感受就是:和传统推理模型不一样。不话痨,既不会把冗长的思考过程全展示出来,回答也言简意赅,反应迅速。

先让它写一个前端界面,设计一张用户卡片。完成度极高,几乎完美实现了所有关键指令:字体样式(斜体)、头像形状、布局居中都毫无问题,甚至对「主色调石板蓝、辅助色白」的抽象视觉要求,也精准拿捏。
提示词:请生成一个蓝紫色主题(主色调为 #6A5ACD,辅助色为白色)的现代用户卡片组件。卡片内必须包含:1. 用户头像(圆形占位符);2. 用户名;3. 一句签名(使用斜体字);4. 一个蓝色关注按钮;5. 整体布局居中。
接着,又让它设计一个漂亮的倒计时网页。渐变背景让人眼前一亮,意外地漂亮,也显得很有设计感。得益于「语法–功能–美学」混合奖励机制,Ling-1T不仅懂代码逻辑,也开始学会了审美。
提示词:设计一个好看的倒计时网页。
因为上面的倒计时功能有 bug,我们又抽了一次卡。下面这个虽然色彩不如前一稿惊艳,但它的「巧思」藏在底部文案里,比如「时间晶体」、「量子纠缠倒计时」。倒数功能也完全正常。
提示词:请给前沿科技媒体机器之心设计一个前沿风格网页,要求置顶部分滚动播出实时AI新闻。这一次意外惊喜来自鼠标轨迹,有粒子浮动效果,科幻又浪漫。
除了编程设计,Ling-1T 还能发挥科学与逻辑推理能力,化身大众的学习助手——答疑解惑,甚至能帮人撰写报告。
我们先用 2025 年数学新课标 I 卷 的第15 题(解答题)试水,结果轻松过关。

那它能不能把复杂的东西也讲得通俗易懂?今年,2025 年诺贝尔物理学奖颁给了三位美国科学家,表彰他们通过实验验证了量子隧穿效应。
我们请 Ling-1T来讲讲:什么是量子隧穿效应?结果,它用「穿墙术」的比喻,把粒子「借力」穿透势垒的概念讲得直观又准确,没有跑偏,还有效地降低了理解门槛。
逻辑也很清晰:先对比经典世界与量子世界的差异,再解释原理、举例印证,最后总结关键点。

对《星际穿越》里的「虫洞」科普也同样出彩。没有令人头疼的公式,只有想象力:苹果、折纸、牙签的比喻,瞬间构建出一个直观的几何模型,把「弯曲宇宙的捷径」讲得入木三分。表格、问答、总结,层次分明、言简意赅。

紧接着,我们测试它的创意写作能力,关键不只是「会写」,而是「写得有意思」。无论是内容营销、广告文案、剧本创作,还是创意辅助,这项能力都能派上用场。
这是 Ling-1T 为一期介绍诺贝尔物理学奖的播客节目所写的开场白。按要求,它必须以《星际穿越》中那首诗为灵感。
结果令人惊喜:它不仅准确锁定了狄兰·托马斯的名作,语言富有张力,连背景音效都契合主题。

下面这篇 800 字的「诺奖物理学奖小红薯文案」,几乎可以直接发布。信息精准、结构清晰、有节奏感,一点都不晦涩。

最后,看看它的执行能力。任务很具体——「介绍武汉附近私藏、小众徒步路线,自驾不超过 2 小时,适合周末短期出行。」
现实中,无论个人还是企业,往往都需要模型去执行更复杂的任务:联网搜索、数据库查询、代码计算,甚至对接内部系统。拥有「工具调用」能力,意味着 Ling-1T 不只是「回答问题」,而是真正能调动外部资源、完成任务的执行者。
从结果来看,表现稳健。推荐的地点真实存在(没有幻觉),甚至不少地方连本地人都没去过,确实「小众」。
更有意思的是,排在第一的选项略超两小时车程,模型不仅自知,还说明理由——「虽然超时,但景观稀缺,值得破例」——这种自洽判断颇有人味。
整份结果不仅提供地理与交通信息,还涵盖季节性建议、专业贴士,落地性极强。

蚂蚁的帕累托改进:
万亿模型,如何更强又更省?
「堆大」不再是答案。Ling-1T 再次释放同一个信号:2025 年的大模型竞争,正在转向效率范式,如何在「大」的基础上实现效率革命。毕竟,真正要让 AI 像扫码支付一样无处不在,关键在于更快、更省、更稳的日常表现。
于是,「大参数储备 + 小参数激活」范式迅速成为突破口,用万亿级能力兜底,用百亿级开销响应。它既不牺牲推理力,也直面算力/成本的长期矛盾,让超大规模模型从实验室真正走入生活。
Ling-1T正是这一路线的样板。手握万亿参数,但每次调用只需百亿级计算资源——复杂问题能扛,响应速度不掉,成本曲线可控。一次漂亮的帕累托式改进,这才是面向产业的正确形态。
那么,「想得快」又能「想得准」,这种平衡从何而来?先说两个关键点:数据和架构。
一方面,提高「摄入知识」质量,超过 20T+ token 的高质量、高推理浓度语料,使得 Ling-1T 从数据层面就具备了更强的逻辑密度与思维深度。
另一方面,它还学会了「按需思考」。虽然每个 MoE 层 拥有 256 位专才,但在推理时仅激活约 50B 参数:每次接到问题,系统只会挑出最合适的 8 位专家参与思考,再由共享专家整合结果。
结果是,万亿级智商背书,百亿级能耗落地,能效比显著抬升。
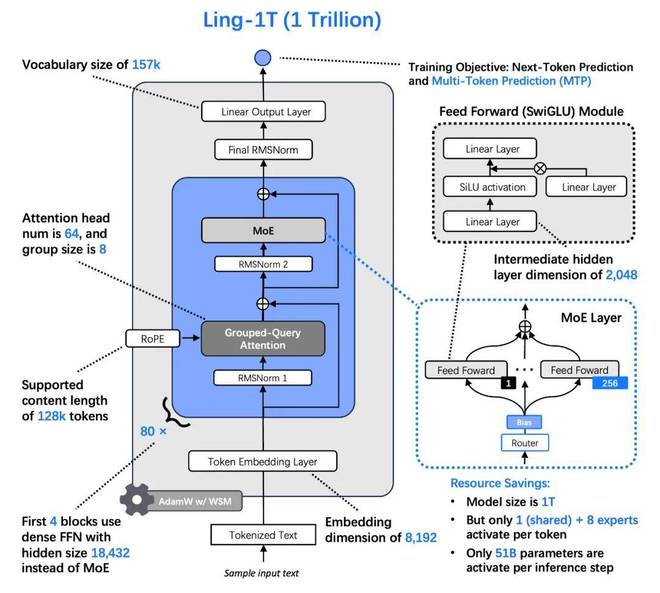
Ling-1T模型结构示意图,一款拥有 1 万亿参数的 MoE(Mixture of Experts)架构大模型,旨在保证强推理能力的同时,实现高效计算与低成本推理。
这套「按需思考」的路径,也带来了实际使用层面的质变。
支持128K 上下文,接近「长记忆」体验——一本书级别内容一口气读完,不丢线索,这对法律、金融、科研等长文档业务尤其关键。
分组查询注意力( Grouped-Query Attention )叠加高效 MoE,使深度理解与敏捷响应兼得,推理速度不再被长上下文拖累。
帕累托改进之二:
巨兽如何更聪明地学习?
除了数据和架构,Ling-1T 的另一个关键创新是把「学得更聪明」落到工程与训练范式上:不是多喂而是精喂,不是「猛灌」而是善练。
为了让模型「吃进去」的每一口,都是高推理密度的知识精华,蚂蚁自建 infra ,提升养分密度。
首先,打造了原生 FP8 混合精度训练平台,为万亿参数模型提供高吞吐、低能耗的算力底座。随后,又构建了基于 统一数据湖宽表(Unified Wide Table on Data Lake) 的 AI Data System,实现样本级血缘追踪,确保每一个 token 都「来源可追、质量可控」。
通过这套基础设施,蚂蚁在 40T+ 语料中提炼出 20T+ 的高推理密度数据,成为 Ling-1T 的核心「思考养料」。
在训练路径上,这套系统并非单一阶段的「猛灌」,而是以三阶段精英教育精细推进:
先用 10T 高知识密度语料打牢通识底座,再以 10T 高推理密度语料强化逻辑链条。中期的 Midtrain 是关键:不仅把「记忆力」扩展到 32K 上下文,更提前注入演进式思维链(Evo-CoT),为后训练阶段预热推理通路,让模型从「会背」过渡到「会想」。
为了让收敛更稳更快,训练节奏控制同样被精细化。
通过 Ling Scaling Laws 自动计算最优参数配置(学习速度、批量大小等),不再靠「手感」;
自研 WSM 调度器(Warmup–Stable–Merge) 替代传统策略,在中期合并多轮训练成果,模拟自然收敛。最终,大模型在综合能力、常识、语言理解、专业知识、数学与代码等多赛道上普遍跑赢旧策略。
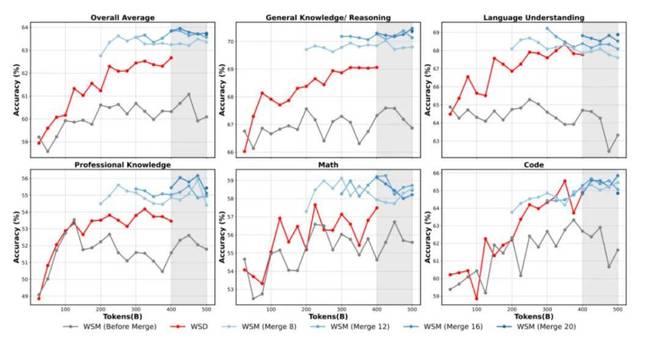
这六个子图代表模型在不同类型任务上的表现变化,比如综合能力、常识推理、语言理解、专业知识、数学和代码能力。蚂蚁在训练调度器上的一个关键突破 WSM(Warmup–Stable–Merge) 相比传统的 WSD(Warmup–Stable–Decay),在几乎所有任务上都带来了明显的性能提升。
进入后训练(强化学习)阶段,关键在于把反馈颗粒度与人类语义对齐。传统 GRPO(词元级)像逐像素修图,细却碎,难以理解整体语义;GSPO(序列级)又太粗,稳定但反馈模糊。
而蚂蚁自研的「锦囊」LPO( Language-unit Policy Optimization ),以「句子」为优化单元,直接在人类最小完备语义单位上对齐奖励与约束,既避免词元级的碎裂,也克服序列级的模糊,把训练目标从「对的词」升级为「对的理」,让模型生成逻辑完整、思维连贯的语言流。Ling-1T 也在高智商与稳健性之间找到新的平衡点。
开源,让「AI 普惠」
行业认为,AI 竞争,真正的分野不在于谁的模型更强,而在于开源与闭源的路线之争。越来越多的中国力量,正在选择前者。
一方面,这是阶段性必然。身处追赶者的位置,开源就像「众人抬车」,能让技术以更低成本、更高速度迭代前行。对于 Ling-1T 这样重工程型的大模型系统,开源社区本身就是一个去中心化的「质量与安全红队」,能显著降低边际改进成本,加快版本演进。
另一方面,中国的优势从不在单一模型本身,而在丰富的落地场景。尤其是金融、医疗等高合规行业,开源的透明性让企业有机会真正「看懂」模型:可以审计决策路径,植入自有知识,在可控的安全边界内释放智能价值。当信任可以被复制,智能才可能被普及。
更重要的是,开源降低了参与门槛。从开发者到中小企业,每一个个体都能以最低摩擦的方式「布点」入场,共建生态。
在开源 Ling-1T 之前,蚂蚁已经用高效的 MoE 架构 与 分层模型设计,将「万亿级能力」拆解成可落地的多种形态——
你可以在手机上运行 Ling-mini,在中小企业服务器上部署 Ling-flash,也可以在云端调用完整体 Ling-1T。
更进一步,蚂蚁不仅开源了模型本身,还开放了让模型持续进化的「底层能力」:从 ATorch 框架到强化学习工具链,让模型研发像 DevOps 一样实现「流水线化」。
这些决定,也更像是一种普惠哲学的践行。当有人用它理财,有人用它写文案,还把它嵌入风控系统、零售网络、金融终端、诊疗系统,当这些能力被频繁调用时,AI 才成为一种日常,像电力与支付那样,无感却又无处不在。
HuggingFace:https://huggingface.co/inclusionAI/Ling-1T
ModelScope:https://modelscope.cn/models/inclusionAI/Ling-1T
GitHub:https://github.com/inclusionAI/Ling-V2
Ling chat(国内用户):https://ling.tbox.cn/chat
ZenMux(海外开发者,提供 Chat 测试与 API 等能力):
https://zenmux.ai/inclusionai/ling-1t
文中视频链接:
https://mp.weixin.qq.com/s/ccGLfIe9CSspVWc3TVf6fA