

近年来,大语言模型在算术、逻辑、多模态理解等任务上之所以取得显著进展,很大程度上依赖于思维链(CoT)技术。所谓 CoT,就是让模型在给出最终答案前,先生成一系列类似「解题步骤」的中间推理。 这种方式可以显著提高模型在复杂推理类任务上的表现,已成为当前最主流的推理增强方法。
但从实际使用和研究结果来看,CoT 的表现并非始终稳定。一些任务中可以明显观察到:
那么问题来了:大模型有没有可能「意识到自己正在犯错」?在 Token 概率不可靠的情况下,是否有其他信号可以指导更可靠的生成?
在这一背景下,合肥工业大学的研究团队提出了一个观点:大模型的内部其实存在一种「隐藏的真伪认知」。这种状态可以形象地理解为「爱你在心口难开」——模型在内部激活中已隐含对推理正确性的判断,但这种判断却在基于 Token 概率的生成过程中被错误地表达。因此,模型即便「口头说错」,其内部表征中仍保留着对纠错的可能。
这篇论文的核心,就是让模型学会用这种隐藏认知来给自己的每一步推理「打分」,进而过滤掉错误的推理链,让 CoT 更可靠。该工作已被 AAAI 2026 录用为 Oral 论文。

研究背景与问题
随着大语言模型在数学推理、逻辑推理与多模态问答等领域的应用不断扩大,人们越来越关注一个核心能力:模型是否能够在生成过程中保持稳定且可靠的推理质量。在实际使用中,模型往往需要连续推导多个中间步骤才能得到最终答案,这使得推理链的质量对整体表现具有决定性影响。
然而,推理链本身是通过生成式过程逐步展开的,其可靠性受到多种因素影响,例如:模型对问题理解的细微偏差、局部步骤的表达噪声、长链推理中的累积误差等。即便模型整体能力足够强,这些因素仍可能导致某些推理步骤偏离正确方向,影响最终回答的准确度。
因此,一个自然且重要的问题是:
在推理过程中,是否存在某种可以反映当前步骤可靠性的内部信号,从而帮助我们判断哪些推理路径值得继续扩展?
大语言模型在生成每一步推理时都会产生丰富的内部激活,这些表示承载了模型对输入、上下文以及当前推理状态的理解。 如果这些激活中包含区分「合理推理」与「错误推理」的信息,那么我们就有可能在生成阶段实时利用这些内部线索,从而提升推理链的整体质量。
基于这一动机,这项研究聚焦于两个关键问题:
论文提出的方案正是在回答这两个问题,并尝试让推理过程在模型原有能力基础上变得更稳健、更具判断力。
方法与创新
论文提出的框架,核心思想是:虽然模型表面生成的推理步骤可能不够可靠,但其内部激活在很大程度上「知道」哪些步骤是正确的。为此,作者设计了以下创新方法:
从多层注意力头中探测「真伪敏感性」
对模型生成的推理步骤进行真伪标注(True/False),然后在模型各层的内部表示上训练简单探针(Linear Probe),测试哪些层对推理正确性最敏感。
结果表明:中间层的特定注意力头能区分「正确步骤」和「错误步骤」,准确率可达 80% 以上。这说明模型的内部确实蕴含潜在的认知信号。
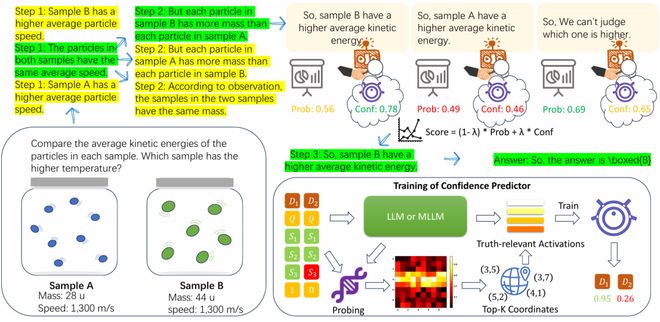
构建置信度预测器(Confidence Predictor)
作者选取最敏感的几个注意力头,将其激活拼接,作为输入训练一个轻量预测器,输出对每一步推理的可信度评分。该评分不基于 Token 概率,而基于模型内部的深层表示,更能反映推理质量。
基于置信度的推理路径搜索(Confidence-Guided Search)
结合模型生成概率与可信度,设计新的推理扩展策略:
通过此评分筛选最可信的推理路径,使生成过程能够:
从而提高整个 CoT 推理链的稳定性。
实验结果
论文从两个层面系统评估了所提出方法的有效性:(A)可信度预测器本身是否可靠?(B)将预测器用于推理路径选择后,整体推理是否更准确?
下面分两部分介绍。
A. 置信度预测器的评估
作者首先评估模型内部激活是否真的携带「推理真伪」的可判别信号,以及预测器能否有效地从激活中提取这种信号。核心实验包括:
通过在模型不同层、不同注意力头上训练线性探针,研究者获得了以下发现:
这一结果表明:模型在内部表征中「隐含地知道」某一步推理是否正确。预测器正是利用这些「高敏感」注意力头,因此具有良好的理论基础。
论文进一步引入 ECE-Loss 进行校准,使预测的可信度分数更可解释、更稳定。实验显示置信度预测器得到的可信度分数校准性更佳,即得到的置信度分数更贴近真实的真伪概率值,作者用 ECE、Brier 和 AUC 这三个校准指标以及多种置信度量化方法来评估,如下表:
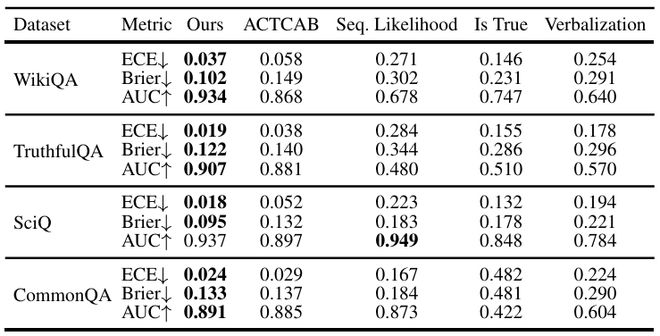
这证明预测器不仅能区分真伪,还能提供更具校准性、可用于决策的连续置信度评分,适合作为搜索策略的依据。
B. 基于预测器引导的推理性能
论文将可信度预测器应用于推理路径选择,并在多个 Benchmark 上进行验证,既包括纯文本推理任务(单模态),也包括视觉–语言混合的多模态推理任务。评估数据集覆盖数学、逻辑以及常识推理。
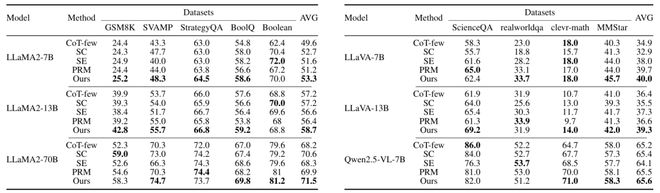
结果表明,方法在每种设置下均取得了优异性能。与相同设置下的少样本思维链(Few-Shot CoT)相比,该方法在大多数测试中均展现出显著提升。 例如,在单模态任务的 SVAMP 数据集上,该方法相较于少样本思维链提升了 5 个百分点(48.3 对 43.3);在多模态任务的 RealWorldQA 数据集上,实现了 10.7 个百分点的提升。
总体而言,无论是在数学与符号推理、常识推理任务中,还是在单模态与多模态任务中,该方法在大多数情况下都优于基线模型少样本思维链以及其他 Baseline。这充分表明,从模型内部状态中提取的置信度能够有效引导生成更可靠的推理链。
消融实验表明:可信度预测器对推理提升至关重要。如下图所示:
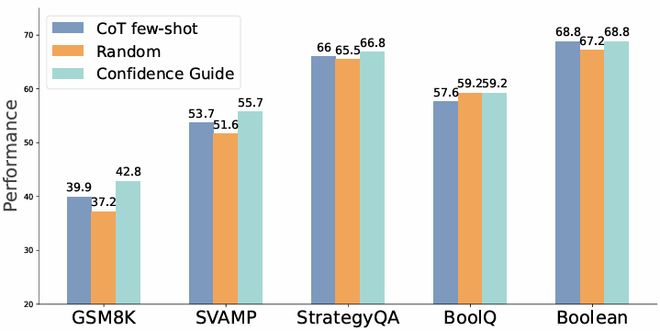
若将候选推理步骤「随机选择」而非依据可信度,本方法性能显著下降。随机策略在若干任务上甚至低于 Few-Shot CoT Baseline。
作者信息
一作:陈紫军,合肥工业大学博士生,主要研究方向为大模型概率可靠性,曾在 AAAI、COLING 等顶级会议上发表论文。
通讯作者:胡文波,合肥工业大学计算机与信息学院副教授,黄山青年学者。主要研究方向为机器学习,包括贝叶斯概率机器学习、人工智能安全以及科学人工智能。