
谷歌Nano Banana掀起的狂欢海啸,完全不亚于ChatGPT横空出世。
它,号称是PS的终结者。
以往,Photoshop耗费数个小时完成的修图,Nano Banana仅用一句话,最多30秒神速完成。

意想不到的是,谷歌发布不到10天后,国产版「Nano Banana」诞生了!
今天,Vidu Q1全球同步上线「参考生图」功能,一举击碎国内参考天花板,让图片生成进入「生产级」时代。

一次扔进7张图,Vidu Q1参考生图稳拿捏,逼真还原的同时,还能随心所欲创作。
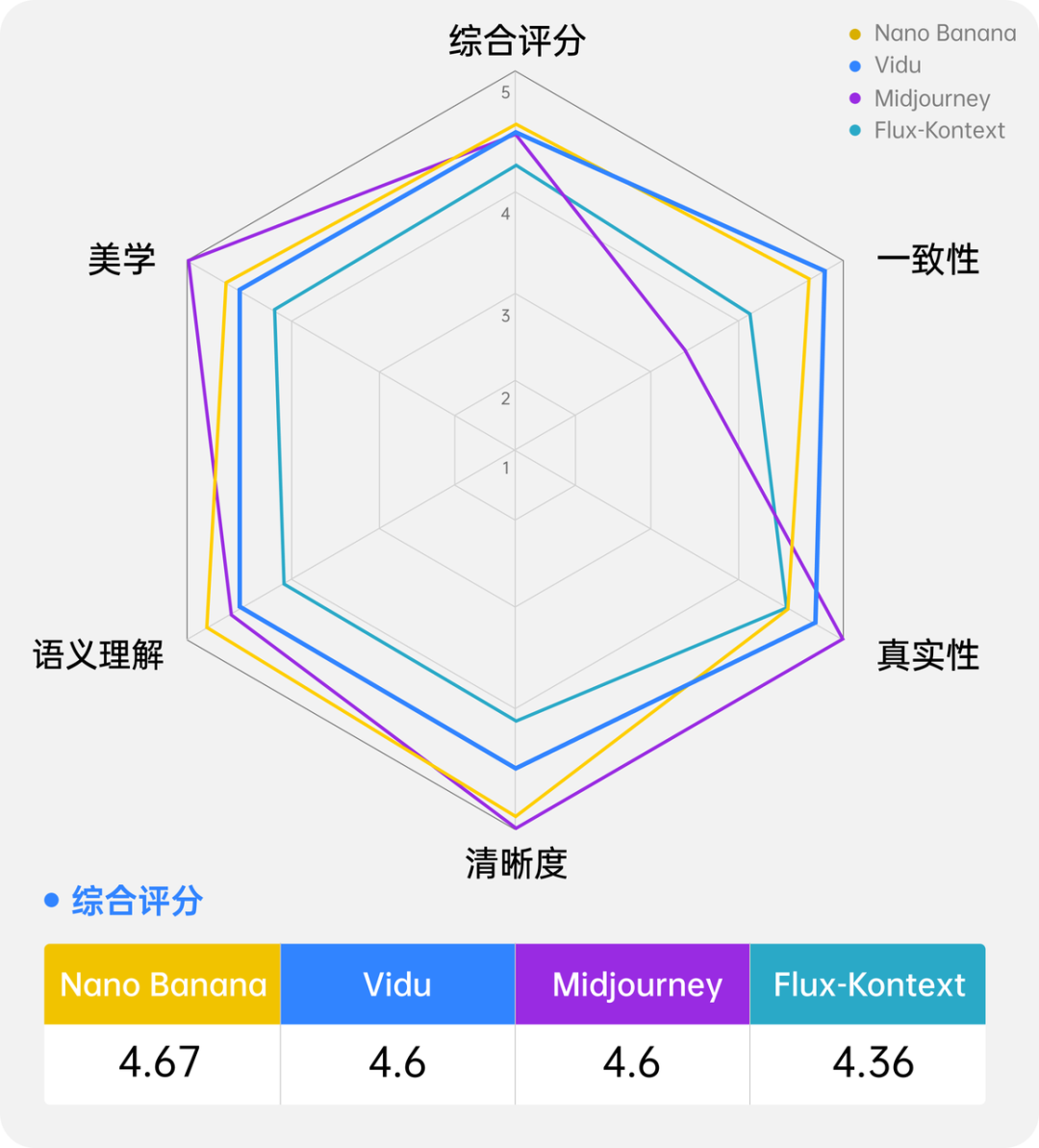
在一致性、美学、真实性、清晰度、语义理解综合评分上,Vidu Q1参考生图完全碾压Flux Kontext,与Nano Banana相媲美。
Vidu Q1参考生图的易用性,简直就是创作者的「生图利器」,万物皆可合成、万物皆可替。
外国网友激动地表示,「这简直是,目前最佳的AI参考生图的工具。每次输出的效果绝了」!

还有人盛赞Vidu Q1参考生图一致性,并称,Vidu这种低调的实力派,真正推动了AI领域的创新。

下面就来扒一扒Vidu Q1参考生图的「合成大法」,保你看完脑洞大开。
国产「Nano Banana」出世
Vidu Q1「参考生图」的核心——只要参考够多,就能还原够真。
一次7张图,打破国内天花板
Vidu Q1支持单次最多7张参考图,这一能力不仅在国内处于领先地位,更是行业顶尖水平。
相较之下,市面上的竞品AI工具,通常仅支持1-3张参考图。
在处理多元素场景时,比如同时参考多个人物形象,很多工具的生成结果往往支离破碎,不仅模糊,且经常出现相似但不像的情况。
Vidu Q1参考生图则突破了这些限制,可自由组合多张图片,实现无缝融合。
举个栗子,同时输入如下五张图,一张主体,一张背景,还有三张道具图,并提示小熊做出抛球的动作。

prompt:的人物和的车一起出现在的场景里,两脚分开站在车前,两手张开用和的球做着小丑抛球的动作,和在画面中小一些
如下的输出图中,Vidu Q1参考生图可以做到高效整合,生成出流畅、自然的结果,毫无违和感。

接下来,上一个难度的,不仅要为主体换衣,还要融合字体、马这些要素。

prompt:穿着服装,头戴帽子,骑着马,背景是,右上角印有logo

Vidu Q1参考生图还能同时做到「AI参考+AI生成」,将所有的参考放在一张图中,并给出一个完整的提示。

prompt:一个明亮的北欧风房间,木质书桌上放着粉色笔记本和玻璃杯,旁边花瓶里有一枝粉色花朵,桌角有小多肉植物。地上有毛绒坐垫和白色帆布包。一位戴玫瑰金圆框眼镜、穿米白色针织背心和白裙的温柔女生站在房间里,安静地看着书桌,整体氛围清新治愈。
可以看到,不论是图中有的,还是指令要求的,Vidu Q1参考生图都能做到完整还原。
其实上述案例是一次参考了10个物品,这意味着只需把多个物体放在一张图中,其实Vidu Q1参考生图可以参考的物体数量远不止7张,而是无上限的,简直是生图领域的大杀器。

主体一致性,全面超越
更令人惊叹的是,Vidu Q1参考生图在一致性上的表现堪称惊艳,全面超越了Flux Kontext等同类产品,甚至也超过了Nano Banana。
无论是多人互动、多场景切换,还是多次生成,它都能保证人物的面貌、特征高度稳定。
诸如多角色混淆、人物走样、服饰或细节丢失等常见问题,在Vidu Q1参考生图中几乎不存在。
这种卓越的主体一致性,正是Vidu Q1参考生图迈向「生产级应用」的核心优势。
相较于Nano Banana,Vidu Q1参考生图真实表现又如何?

prompt:图1人物拿着图2展示
就来一张简单的,图1拿着图2展示,Vidu Q1参考生图非常自然地呈现,而Nano Banana米饭摆放有些不合理。

左:Vidu;右:Nano Banana
再来看一个案例,不同模型的表现又如何?

prompt:图1人物拿着图3吃图2
可以看到,Vidu Q1和Nano Banana保持了原图的高度一致性。
而Flux.1 Kontext在衣服、人脸一致性上表现欠佳,且蛋糕比例失调,没有体现勺子这个元素。

从左至右:Vidu Q1、Nano Banana、Flux.1 Kontext
假设让Vidu Q1和Nano Banana,补全如下这张彩虹图,谁做的更好?

prompt:把彩虹的右半边补全,形成半圆彩虹
实测可以发现,Nano Banana未能准确理解提示词中,彩虹补全要求,仅生成了另外一半彩虹。
而Vidu Q1参考原图,成功补出未出现在图片中的另一半彩虹,展现了极强的画面理解力和一致性。

左:Vidu Q1;右:Nano Banana
高还原度,所见即所得
Vidu Q1参考生图不仅支持多张参考图输入、主体一致性出色,还在还原度上实现了质的突破。
它在保持参考图特征的同时,能生成高度贴近原始输入内容,真正做到「所见即所得」。
业内常见的参考模糊、相似却失真的问题,在Vidu Q1参考生图面前迎刃而解。
接下来,要PK就来一个复杂的,一次上传五张图,具体如下:

prompt:侧面视角,站在灶台边锅前手中拿着大勺搅拌,锅里装着,背景,动漫风格,2D,动画风格,
显然,Nano Banana在主体一致性上表现欠佳,核心元素如衣袖、领口花纹细节,与原图差异明显。
而Vidu Q1展现了惊艳的实力,不仅完美还原动漫主体,连手套、衣服等细节都实现了1:1精准复刻。

左:Vidu;右:Nano Banana
再比如,参考图中男子,将其背景P为教室。

prompt:参考图中人物,修改背景为人物在班里座位上认真听课
以下四大模型,在背景生成上各有特点。
但在人物脸部特征、服饰细节上,Vidu Q1参考生图都做到了最逼真还原。
Nano Banana生成的人物双眼皮消失,发型与服装均出现变化;Midjourney给人物戴上眼镜,无中生有;Flux.1 Kontext生成的人物双眼皮模糊,脸上还多了许多斑点。

从左至右:Vidu Q1、Nano Banana、Midjourney、Flux.1 Kontext
创意玩法上天,只有想不到的
一款AI工具,仅做到一致性还远远不够,还需拥有强大的创作自由度,满足多样化的创意需求。
最近,Nano Banana被全网整出各种花活儿,让人直呼上头。
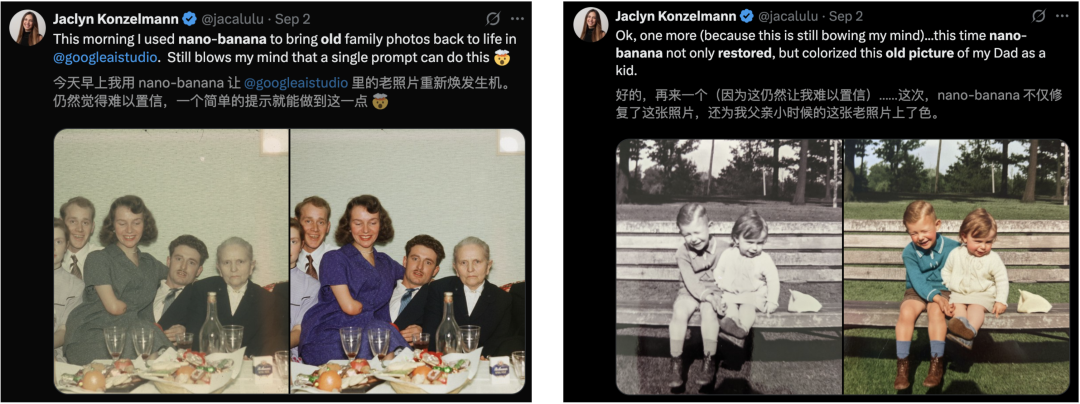
比如,3D人偶手办、老照片修复/上色、多角度视图生成、真人Cosplay、名人合影等等。
一个比较火的玩法,修复老照片,让无数人泪目。
Vidu Q1参考生图创作自由度,同样令人惊叹!
仅需「一张图+一句话」,它就能轻松实现换装、换背景、换角色、换道具。
甚至,Vidu Q1参考生图也能一键直出人物手办。

输入线稿图后,Vidu Q1魔法棒一挥,瞬间就能变成桌面上的3D立体摆件。

prompt :变成三维立体建筑摆在桌子上,涂上颜色
顺便......还能帮你上色。

prompt:变成三维立体建筑摆在桌子上,建筑物替换成木头材质,草木替换成绿色,最下面的水系替换成蓝色
假设手里有一张北京著名标志建筑图,它能变成由金属质感的立体冰箱贴。

变成金属质感的冰箱贴
万物皆可合成
简单的两张图合成,一键实现换装、换背景、换风格。
马斯克一秒换装:

现实中,马斯克没尝试过这样的穿衣风格!
同理,演员一秒换上戏服,马上知道古装戏上装效果:

Vidu Q1参考生图不仅能实现一键换装,更精细的面具,也能一键搞定。
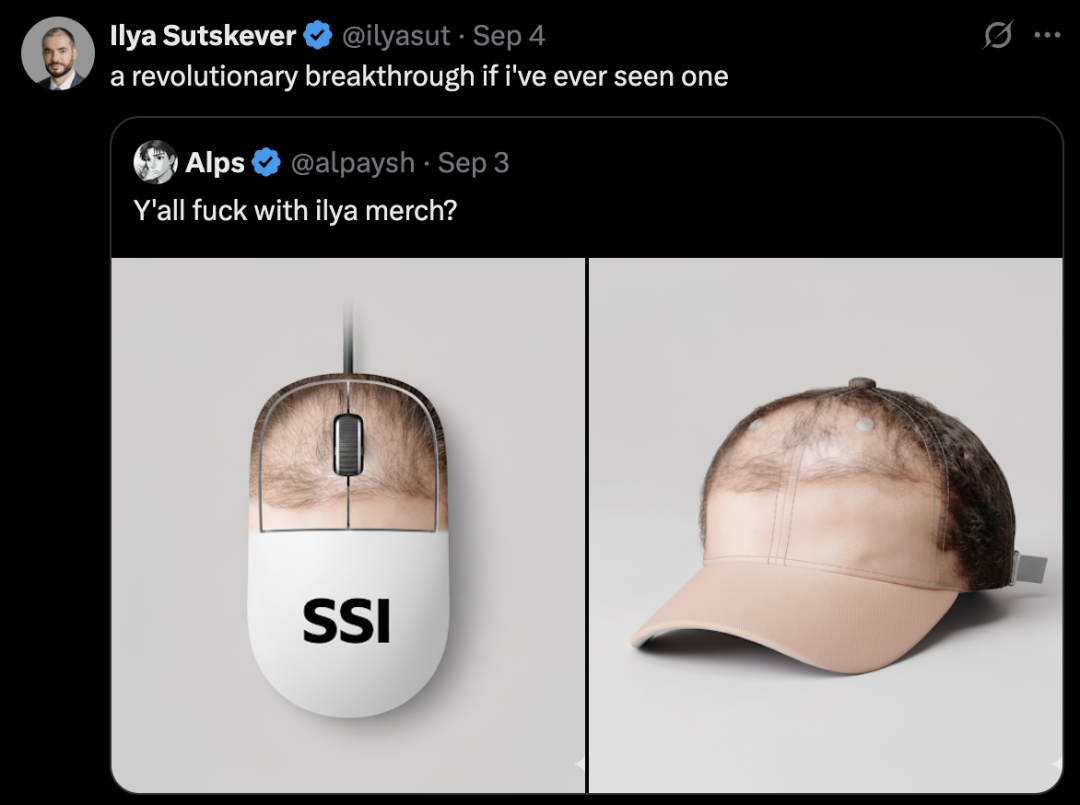
比如,llya戴上三星堆黄金面具,Vidu Q1参考生图还原度高,保留了Ilya标志性的「短发」。

最近,一款帽子「让人头秃」,Ilya惊呼「革命性突破」:
发际线本已稀疏的Ilya,Vidu Q1参考生图生成的戴上帽子的效果是这样的:

不过要让小扎戴上这顶帽子,只能靠AI了。Vidu Q1参考生图尝试一把,效果逼真,AI看了都得直呼离谱:只有碳基智能才能想到的!

不止是真人照片,肖像画中的人物在Vidu Q1参考生图中也可以复活。比如,十一国庆快来了,可以让名画+名建筑,古往今来,五湖四海,任由AI打卡。
比如,蒙娜丽莎打卡北京地标祈年殿:

光影、建筑细节、背景人物,真实感拉满。
类似的例子,可以换其他背景。比如,让汽车登火星:

还可以反向操作,让古代名人体验现代生活,代言各种现代产品。
比如,北宋文豪苏轼如果会弹吉他,大江东去该多豪迈?丙辰中秋,他又该如何表达对弟弟子由的思念?

苏轼弹吉他
甚至古代的仕女都能免费给你打广告。

贵妃醉酒:茅台版
在Vidu Q1参考生图中,还可以让图片中的人物,摆出各种Pose。
比如,现实中闹掰了的Ilya和奥特曼,利用Vidu Q1的参考生图,完全可以在「赛博世界」中重归于好,一起比心。

让鲁迅和马斯克跨越时空,拍一张合影。

prompt:图1与图2合影
Vidu可以解放创意,让人放飞想象:主体一致不跑偏,风格融合更自然。
而且合成2张图只是Vidu Q1参考生图的基础操作。
Vidu Q1支持多图参考,这就能满足复杂剧情、合影、多角色电商等场景。
Vidu Q1参考生图在还原高度一致基础上,还支持产品、道具、场景、光线等任意切换,真实性极强。
万物皆可替
AI一键换装
它能一键生成着装效果,宛如24小时在线的专属搭配顾问。
前段时间,男友Travis Kelce向霉霉求婚,配文「你的英语老师和体育老师要结婚了」掀爆全网。

说不定,许多歌迷们迫不及待地想看到,霉霉提前穿上婚纱的样子。
上传一张霉霉、一张婚纱图,还有一张现场图,Vidu Q1帮你如愿。

最终输出的图,让人眼前一亮,穿上婚纱后的霉霉简直美若天仙。

不仅是大明星,每个人都可以轻松实现一键换装。
网购一件衣服不知款式合不合身,上传一张个人照片,有了Vidu Q1,即可在线秒换春夏秋冬的衣服。

分别输入不同季节服饰后,换装瞬间完成了,不论哪一款穿着都好看。


又或是,把小红书的OOTD全部试一遍。

从着装到配饰,简直一绝。

如果你是一名设计师,想看看手办的格子纹理效果,输入相关物料图片,Vidu Q1参考生图瞬间实现。

或是一款已打好版的衣服,想要尝试不同花纹,Q1也可以玩儿出不同花样。

甚至,你还可以替换图中特定的对象。
比如,现代版「狸猫换太子」:女人手里的小孩换成宠物或者卡通人物。

或者换成史迪奇

即便替换的对象,在图中比较小,也没关系,比如把小女孩手中的牛奶替换为橘子汁。

Vidu Q1还能让你「云游」世界,天天晒出不一样的朋友圈,十一假期可以利用AI拍出完美大片了。
从相册中,上传一张自拍照,以及一张布达拉宫图,P图瞬间完成,人物和背景超自然融合,可以发圈了。

世界名画,整出花活
再以马格利特一幅世界名画《人类之子》为模板,玩一场「绿色苹果」大替换。
一句话换成南瓜,位置也是非常精准,而且人物衣服、颜色保持着高度一致性。

将南瓜放大、再放大,就得到了如下的样子。

换个道具,一只粉色的拖鞋。

这次,再换个人物主体——黄仁勋,老黄的皮衣、眼镜,完美还原。

两幅世界名画,又能碰撞出怎样的火花?
梵高的《星夜》和马格利特《人类之子》完美融合,堪称孤品。

花样玩法
《大话西游之大圣娶亲》中,孙悟空戴上金箍虽获得了无边的法力,却没能保护好心爱的紫霞仙子。

不如,就让Vidu Q1挽回这份「遗憾」。

老照片糊到看不清,让Vidu Q1增强清晰度并换个背景,只能说太惊艳了。

和霉霉同框,自然到根本看不出来是P的。


狂「卷」一致性
解锁AI生产级应用
从「参考生视频」,再到「参考生图」,Vidu的每一次进化是其在「一致性」赛道上又一次发力。
为什么他们如此执着于「一致性」?
回想AI视频发展历程,从Sora惊艳亮相,再到Runway Gen-4、Luma Ray 2、Midjourney V1等模型不断迭代,最初让人惊叹「AI终于能生成视频了」。
但很快,问题就暴露了:AI生成视频往往风格跳跃、人物面目全非,细节更是随时崩坏。
想象拍一部广告,主角的脸从开场到结尾最后一帧变换三次,结果可想而知。

在国内,生数科技很早就洞察到这一痛点。
去年7月,Vidu 全球首推「参考生视频」功能,以参考图为「锚点」,确保生成过程不偏航。
这恰恰提升了AI视频一致性,人物不会变形,风格也不会跳脱。
比如上传一个女孩、帕台农神庙、一束花,Vidu丝滑地将其呈现在一个场景中。
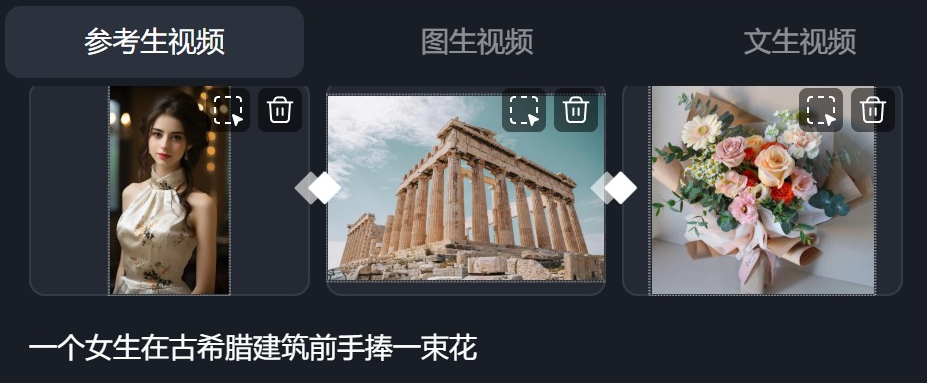

从这里开始,生数就把一致性从视频层面,扩展到了多模态可控。
今年4月,Vidu Q1进一步升级,升级了首尾帧运镜,加入了文生音效等功能,让一致性覆盖了视觉、音频。
VBench评测中,Q1勇夺文生视频双榜第一,力压Sora、Gen-3。

如今,焦点来到了最新的Vidu Q1「参考生图」功能,同时7张图,将一致性推向高峰。
做到了多人、多场景下高一致性,还具备了创作自由度,让万物皆可合成、皆可替、皆可变。
图是基础,视频是延伸——先从「参考生图」生成素材,再无缝转为动态视频。
整个过程,一致性贯穿始终,实现了「精细化可控」的闭环。
不难看出,一致性开启了AI视频「生产级应用」的新纪元。这意味着,它不再是人们手里的娱乐玩具,而是规模化落地的生产力引擎。