

近期,快手 Kwaipilot 团队推出了KAT 系列两款突破性 Agentic Coding 大模型开源 32B 参数模型 KAT-Dev-32B闭源旗舰模型 KAT-Coder
这两款模型在 Code Intelligence 领域分别体现出轻量级的超强表现和极致性能。其中,在 SWE-Bench Verified 上,KAT-Dev-32B 展现出强劲性能并取得了 62.4% 的解决率,在所有不同规模的开源模型中排名第 5。与此同时,KAT-Coder 以 73.4% 的解决率在 SWE-Bench Verified 上取得了极佳的单模型表现,比肩全球顶尖闭源模型。
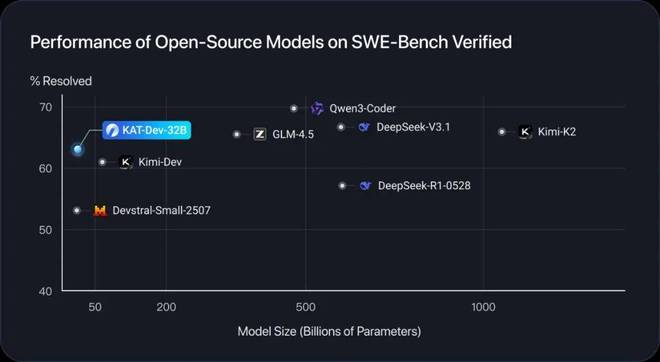
图 1:在 SWE-Bench Verified 上,和全尺寸开源模型对比,KAT-Dev 用极小的模型尺寸取得了第一梯队的性能
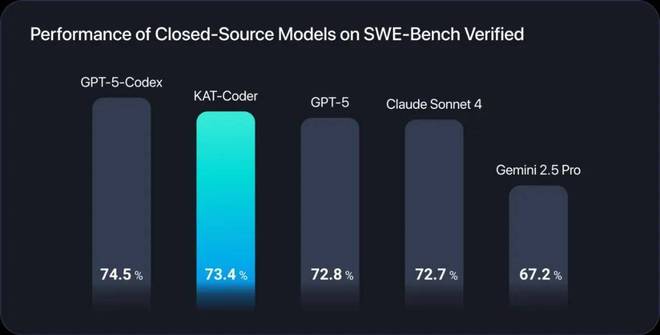
图 2:在 SWE-Bench Verified 上,KAT-Coder 取得极佳的单模型表现,比肩全球顶尖闭源模型性能
模型开源和 API 开放
KAT-Dev-32B 已在开源模型托管平台 Hugging Face 上线,可供进一步研究和开发使用。KAT-Coder 模型的 API 密钥近期也在 “快手万擎” 企业级大模型服务与开发平台上开放申请,用户将能够通过 Claude Code 等工具直接访问并进行编码。
核心贡献点摘要
KAT-Dev-32B 和 KAT-Coder 在多个训练阶段进行了创新和优化,包括 Mid-Training 阶段、监督微调 (SFT) 阶段、强化微调 (RFT) 阶段,以及大规模智能体强化学习 (RL) 阶段,具体如下:
KAT 系列模型的核心技术路线
一、Mid-Training
Kwaipilot 团队对经过预训练的模型进行了两阶段训练,该阶段被称为 Mid-Training。在其中的第一个阶段,增强了模型与 “LLM-as-Agent” 相关的全方位能力,包括但不限于以下几种能力:
二、监督微调 (Supervised Fine-Tuning, SFT)
在第二阶段,Kwaipilot 团队收集了大量人类工程师标记的真实需求交付轨迹,并基于此合成了大量的轨迹数据,进一步对模型进行训练,以增强其端到端需求交付的能力。其中覆盖了多种任务类型:
八大用户任务类型:
八大用户编程场景:
三、强化微调(Reinforcement Finetune,RFT)
在这一阶段,Kwaipilot 团队在强化学习流程的基础上,额外引入了多个 ground truth 用于轨迹探索的指导,提升 rollout 效率,从绝对 reward 到衡量与 ground truth 的差异,提升了强化学习阶段的效率和稳定性。
从直接给定绝对 reward 更新为衡量 rollout 样本和 ground truth 之间的相对差异给了强化学习更稳定和更准确的奖励信号,同时也会在 rollout 阶段实时监督样本的正确性,并及时终止与 ground truth 有明显偏离的样本生成,这也给强化学习带来了更高的样本效率。
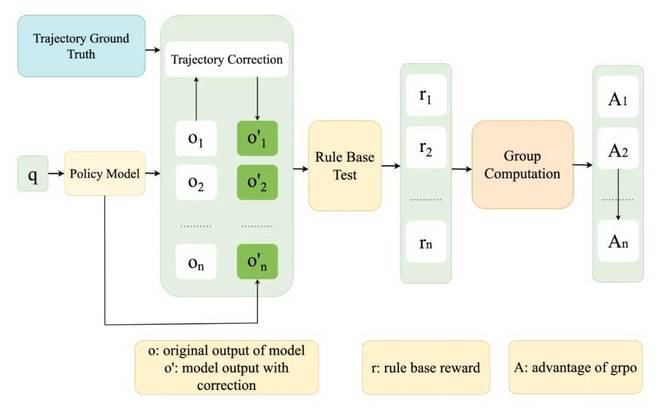
图 3:在强化微调(RFT)流程中,引入教师轨迹作为指导
经过三阶段的训练,团队获得了为 RL 阶段准备的冷启动模型,RFT 的加入也为 SFT 和 RL 之间构建了桥梁。
四、大规模 Agentic RL
1、基于熵的树剪枝(Entropy Based Tree Pruning)
Kwaipilot 团队发现,即便使用上述技术,对完整树中的所有 token 进行训练的成本仍然过高,因此亟需设计一种能够优先聚焦于携带最强训练信号节点的机制。
为此,团队将轨迹压缩成一个前缀树,其中每个节点表示一个共享前缀,每条边对应一段 token。在固定的计算预算下,目标是只保留最有价值的节点进行训练。团队基于树中聚合的熵信号和节点被到达的可能性来估计节点的信息量,并按照重要性顺序扩展节点来剪枝树,直到预算耗尽。额外的启发式方法确保保留结构上的重要区域(例如,工具或内存事件),并维护局部上下文以稳定训练。这种基于熵的剪枝大幅减少冗余计算,同时保留大部分有效的训练信号,从而实现显著的吞吐量提升和更低的总体成本。
2、RL infra:自研 SeamlessFlow 框架
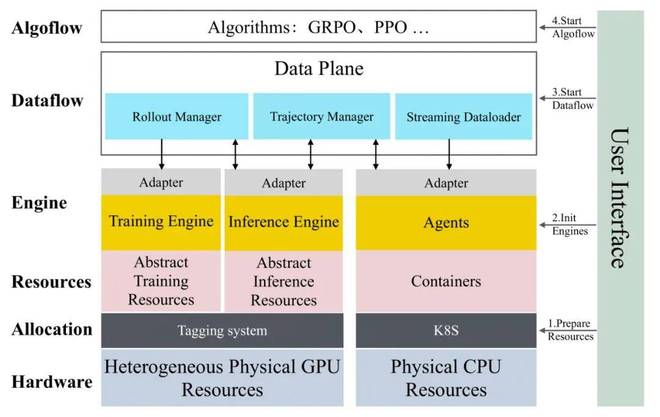
图 4:Kwaipilot 团队自研的 RL 训练框架 SeamlessFlow 架构
为扩展 RL,必须将 RL 训练与智能体的多样化内部逻辑完全解耦,同时最大化异构计算架构的利用率。遵循 SeamlessFlow 的设计,Kwaipilot 团队在智能体和 RL 训练之间设计了一个专门用于轨迹树管理的中间层,确保两者之间的严格分离。此外,采用提出的标签驱动调度机制来协调异构集群中的任务分配,从而最小化管道气泡并维持高吞吐量训练。
3、统一环境接口和企业级 RL 数据构建
Kwaipilot 团队还通过统一不同 RL 执行环境的部署和评估接口,使任何新添加的环境都能以低成本无缝集成。这种统一设计为跨异构数据源和任务类型扩展 RL 训练奠定了坚实基础。具体到软件开发场景,团队聚集于三个基本组件:与相应分支代码配对的问题描述、可执行环境和可验证的测试用例。
Kwaipilot 团队从开源仓库收集拉取请求和相关问题,并根据这些仓库的星标、PR 活动和问题内容过滤低质量数据,随后系统地为每个收集的实例构建可执行环境镜像并生成单元测试用例。除了软件工程数据,团队还纳入了其他可验证领域,如数学和推理任务,进一步丰富了 RL 信号的多样性。
更重要的是,除了开源数据,团队还进一步收集并利用来自真实世界工业系统的匿名企业级代码库进行 RL 训练。与仅在公共仓库(如 GitHub 上的仓库)上训练不同,这些仓库通常包含较简单的项目,而这些大规模、复杂的代码库 —— 跨越多种编程语言并代表真实的业务逻辑 —— 让模型接触到更具挑战性的开发场景,为 RL 提供了高价值的资产。训练智能体解决这些真实世界的工业问题不仅增强了学习的鲁棒性,还将所得模型的编程能力建立在现实的生产级环境中。
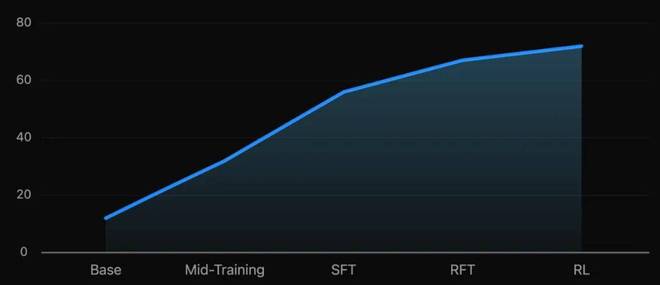
图 5:在 SWE-Bench Verified 上,各阶段训练对模型的性能影响
模型效果展示
KAT-Coder 模型具备强大的代码生成能力,可独立完成完整的项目开发,通过调用编程工具可实现从交互式游戏到代码重构等多样化编程任务。用户仅需描述需求,模型即可交付完整的代码解决方案。
1、星空效果

2、水果忍者

3、代码重构
大规模 Agentic RL 后的涌现能力
对经过大规模 Agentic RL 训练后的模型进行分析,Kwaipilot 团队观测到了两个显著的涌现现象:
对话轮次显著降低:模型倾向于用更少的交互轮次完成任务,相较于 SFT 模型,平均对话轮次下降了 32%;多工具并行调用:模型展现出同时调用多个工具的能力,而非传统的串行调用。
团队推测,这源于轨迹树结构带来的隐式优化压力,使模型自然形成效率偏好与并行调用能力。
效率偏好的形成:在轨迹树结构中,较短的路径(更少的对话轮次)会被更多的训练样本共享。这创造了一个隐式的优化压力:模型倾向于学习更高效的解决方案;并行化的自然选择:在树结构中,多工具并行调用创造了更多的分支可能性,这些分支在训练时被独立处理,使得模型能够同时探索多个工具组合。同时熵剪枝机制(Long-term Entropy Pruning)保留了信息量较大的节点,而多工具调用节点往往具有更高的熵值,使模型逐渐学会了 "批处理" 思维。
未来展望
Kwaipilot 团队将持续探索代码智能的前沿领域,开拓创新可能:
增强工具集成:与流行的 IDE、版本控制系统和开发工作流深度集成,创建无缝的编码体验。多语言扩展:扩展 KAT 模型能力以覆盖新兴的编程语言和框架,确保全面的语言支持。协作编码:探索多智能体系统,让 KAT 模型能够在复杂的软件项目上协同工作,实现前所未有的协作。多模态代码智能:集成视觉理解能力,处理架构图、UI 设计、调试截图和文档图像以及代码,使开发过程更加直观和高效。
原文链接:https://kwaipilot.github.io/KAT-Coder/